
Как исключить из индексации страницы с определёнными параметрами в URL и другие техники контроля индексации сайта поисковыми системами
19.06.2018
Оглавление
2. Контроль индексации в файле robots.txt
2.2 Запрет индексации страницы с определёнными параметрами с помощью robots.txt
2.3 Запрет индексации поисковыми системами, но разрешение для сканеров рекламных сетей
2.4 Запрет индексации всех страниц со строкой запроса
2.5 Запрет индексации страниц с определённым параметром, передающимся методом GET
2.6 Запрет индексации страниц с любым из нескольких параметров
2.8 Как закрыть сайт от индексации
2.9 Разрешение всем роботам полный доступ
2.10 Запрет всем поисковым системам индексировать часть сайта
2.11 Блокировка отдельных роботов
2.12 Разрешить индексировать сайт одной поисковой системой
2.13 Запрет на индексацию всех файлов, кроме одного
3. Как проверить работу robots.txt
4. Запрет индексации страницы с помощью мета тега robots
5. Запрет индексации с помощью заголовка X-Robots-Tag в HTTP
6. Блокировка доступа поисковым системам с помощью mod_rewrite
7. Как запретить роботам доступ к ссылкам на определённом порту
8. Готовые решения для запрета индексирования сайта поисковыми системами
Вы можете контролировать, какие страницы можно индексировать поисковым системам, а какие разделы сайта закрыты от них
Передо мной возникла задача исключить из индексирования поисковыми системами страницы, содержащие определённую строку запроса (уникальные для пользователя отчёты, каждый из которых имеет свой адрес). Я решил эту задачу для себя, а также решил полностью разобраться с вопросами разрешения и запрещения индексирования сайта. Этому посвящён данный материал. В нём рассказывается не только о продвинутых случаях использования robots.txt, но также и других, менее известных способах контроля индексации сайта.
В Интернете много примеров, как исключить определённые папки из индексации поисковыми системами. Но может возникнуть ситуация, когда нужно исключить страницы, причём не все, а содержащие только указанные параметры.
Пример страницы с параметрами: сайт.ru/?act=report&id=7a98c5
Здесь act – это имя переменной, значение которой report, и id – это тоже переменная со значением 7a98c5. Т.е. строка запроса (параметры) идут после знака вопроса.
Закрыть страницы с параметрами от индексирования можно несколькими способами:
- с помощью файла robots.txt
- с помощью правил в файле .htaccess
- с помощью метатега robots
Контроль индексации в файле robots.txt
Файл robots.txt
Файл robots.txt – это простой текстовый файл, который размещается в корневой директории (папке) сайта, и содержащий одну или более записей. Типичный пример содержимого файла:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/
В этом файле из индексации исключены три директории.
Помните, что строку с "Disallow" нужно писать отдельно для каждого URL префикса, который вы хотите исключить. То есть вы не можете написать "Disallow: /cgi-bin/ /tmp/" в одну строку. Также помните о специальном значении пустых строк – они разделяют блоки записей.
Регулярные выражения не поддерживаются ни в строке User-agent, ни в Disallow.
Файл robots.txt должен размещаться в корневой папке вашего сайта. Его синтаксис следующий:
User-agent: * Disallow: /папка или страница, запрещённая для индексации Disallow: /другая папка
В качестве значения User-agent указана * (звёздочка) – это соответствует любому значению, т.е. правила предназначены для всех поисковых машин. Вместо звёздочки можно указать имя определённой поисковой машины, для которой предназначено правило.
Можно указать более чем одну директиву Disallow.
В файле robots.txt можно использовать подстановочный символы:
- * обозначает 0 или более экземпляров любого действительного символа. Т.е. это любая строка, в том числе и пустая.
- $ обозначает конец URL.
Другие символы, в том числе &, ?, = и т.д. понимаются буквально.
Запрет индексации страницы с определёнными параметрами с помощью robots.txt
Итак, я хочу заблокировать адреса вида (вместо ЗНАЧЕНИЕ может быть любая строка): сайт.ru/?act=report&id=ЗНАЧЕНИЕ
Для этого подойдёт правило:
User-agent: * Disallow: /*?*act=report&id=*
В нём / (слеш) означает корневую папку сайта, затем следует * (звёздочка), она означает «что угодно». Т.е. это может быть любой относительный адрес, например:
- /ru
- /page.php
- /order/new/id
Затем следует ? (знак вопроса), который трактуется буквально, т.е. как знак вопроса. Следовательно далее идёт строка запроса.
Вторая * означает, что в строке запроса может быть что-угодно.
Затем идёт последовательность символов act=report&id=*, в ней act=report&id= трактуется буквально, как есть, а последняя звёздочка вновь означает любую строку.
Запрет индексации поисковыми системами, но разрешение для сканеров рекламных сетей
Если вы закрыли сайт от индексирования для поисковых систем, либо закрыли определённые его разделы, то на них не будет показываться реклама AdSense! Размещение рекламы на страницах, закрытых от индексации, может считаться нарушением и в других партнёрских сетях.
Чтобы это исправить, добавьте в самое начало файла robots.txt следующие строки:
User-agent: Mediapartners-Google Disallow: User-agent: AdsBot-Google* Disallow: User-Agent: YandexDirect Disallow:
Этими строками мы разрешаем ботам Mediapartners-Google, AdsBot-Google* и YandexDirect индексировать сайт.
Т.е. файл robots.txt для моего случая выглядит так:
User-agent: Mediapartners-Google Disallow: User-agent: AdsBot-Google* Disallow: User-Agent: YandexDirect Disallow: User-agent: * Disallow: /*?*act=report&id=*
Запрет индексации всех страниц со строкой запроса
Это можно сделать следующим образом:
User-agent: * Disallow: /*?*
Данный пример блокирует все страницы, содержащие в URL ? (знак вопроса).
Помните: знак вопроса, стоящий сразу после имени домена, например, site.ru/? равнозначен индексной странице, поэтому будьте осторожны с данным правилом.
Запрет индексации страниц с определённым параметром, передающимся методом GET
К примеру, нужно заблокировать URL, содержащие в строке запроса параметр order, для этого подойдёт следующее правило:
User-agent: * Disallow: /*?*order=
Запрет индексации страниц с любым из нескольких параметров
Предположим, нам нужно запретить индексировать страницы, содержащие в строке запроса или параметр dir, или параметр order, или параметр p. Для этого перечислите каждый из параметров для блокировки в отдельных правилах примерно следующим образом:
User-agent: * Disallow: /*?*dir= Disallow: /*?*order= Disallow: /*?*p=
Как запретить поисковым системам индексировать страницы, в URL которых несколько определённых параметров
К примеру, нужно исключить из индексации страницы, содержание в строке запроса параметр dir, параметр order и параметр p. К примеру, страница с таким URL должна быть исключена из индексации: mydomain.com/new-printers?dir=asc&order=price&p=3
Этого можно добиться используя директиву:
User-agent: * Disallow: /*?dir=*&order=*&p=*
Вместо значений параметров, которые могут постоянно меняться, используйте звёздочки. Если параметр всегда имеет одно значение, то используйте его буквальное написание.
Как закрыть сайт от индексации
Чтобы запретить всем роботам индексировать весь сайт:
User-agent: * Disallow: /
Разрешение всем роботам полный доступ
Чтобы предоставить всем роботам полный доступ для индексации сайта:
User-agent: * Disallow:
Либо просто создайте пустой файл /robots.txt, либо вообще не используйте его – по умолчанию, всё, что не запрещено для индексации, считается открытым. Поэтому пустой файл, либо его отсутствие – означают разрешение на полное индексирование.
Запрет всем поисковым системам индексировать часть сайта
Чтобы закрыть некоторые разделы сайта от всех роботов, используйте директивы следующего вида, в которых замените значения на свои:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /junk/
Блокировка отдельных роботов
Для закрытия доступа отдельным роботам и поисковым системам, используйте имя робота в строке User-agent. В данном примере закрыт доступ для BadBot:
User-agent: BadBot Disallow: /
Помните: многие роботы игнорируют файл robots.txt, поэтому это не является надёжным средством закрыть сайт или его часть от индексирования.
Разрешить индексировать сайт одной поисковой системой
Допустим, мы хотим разрешить индексировать сайт только Google, а другим поисковым системам закрыть доступ, тогда сделайте так:
User-agent: Google Disallow: User-agent: * Disallow: /
Первые две строки дают разрешение роботу Google на индексацию сайта, а последние две строки запрещают это всем остальным роботам.
Запрет на индексацию всех файлов, кроме одного
Allow: Указывает на каталог или страницу относительно корневого домена, которые можно сканировать агенту пользователя, определенному выше. Используется, для того чтобы отменить директиву Disallow и разрешить сканирование подкаталога или страницы в закрытом для сканирования каталоге. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса, суффикса пути или всего пути.
Директива Allow определяет пути, которые должны быть доступны указанным поисковым роботам. Если путь не указан, она игнорируется.
Использование:
Allow: [путь]
Важно: Allow должна следовать до Disallow.
Примечание: Allow не является частью стандарта, но многие популярные поисковые системы её поддерживают.
В качестве альтернативы, с помощью Disallow вы можете запретить доступ ко всем папкам, кроме одного файла или одной папки.
Как проверить работу robots.txt
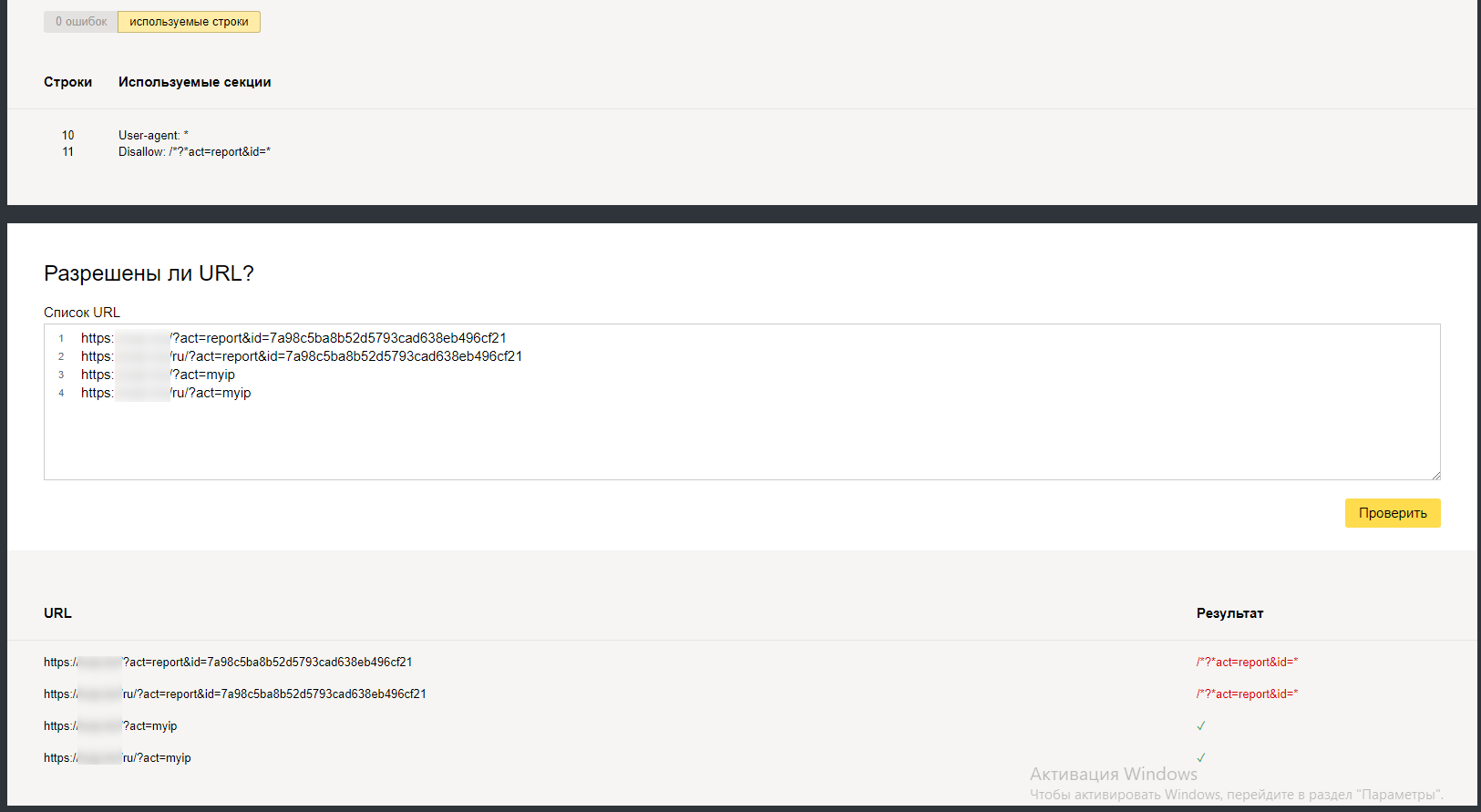
В Яндекс.Вебмастер (https://webmaster.yandex.ru/) есть инструмент для проверки конкретных адресов на разрешение или запрет их индексации в соответствии с файлом robots.txt вашего файла.
Для этого перейдите во вкладку Инструменты, выберите Анализ robots.txt. Этот файл должен загрузиться автоматически, если там старая версия, то нажмите кнопку Проверить:

Затем в поле Разрешены ли URL? введите адреса, которые вы хотите проверить. Можно за один раз вводить много адресов, каждый из них должен размещаться на новой строчке. Когда всё готово, нажмите кнопку Проверить.
В столбце Результат если URL адрес закрыт для индексации поисковыми роботами, он будет помечен красным светом, если открыт – то зелёным.
В Search Console (адрес https://www.google.com/webmasters/tools/robots-testing-tool) имеется аналогичный инструмент. Он находится во вкладке Сканирование. Называется Инструмент проверки файла robots.txt.
Если вы обновили файл robots.txt, то нажмите на кнопку Отправить, а затем в открывшемся окно снова на кнопку Отправить:

После этого перезагрузите страницу (клавиша F5):

Введите адрес для проверки, выберите бота и нажмите кнопку Проверить:

Запрет индексации страницы с помощью мета тега robots
Если вы хотите закрыть страницу от индексации, то в теге <head>…</head> пропишите:
<meta name="robots" content="noindex,nofollow>
Слова noindex,nofollow означают, что страница закрыта от индексации и что поисковые машины не должны следовать по ссылкам, которые присутствуют на этой странице.
Если вы хотите закрыть страницу от индексации, но разрешить поисковым системам следовать по ссылкам на этой странице (чтобы можно было просканировать другую часть сайта), то используйте следующую строку:
<meta name="robots" content="noindex,follow>
Запрет индексации с помощью заголовка X-Robots-Tag в HTTP
Вы можете добавить в файл .htaccess строку:
Header set X-Robots-Tag "noindex, nofollow"
В результате в каждый ответ вашего сайта будет добавляться X-Robots-Tag HTTP заголовок, который запретит поисковым системам индексировать сайт.
Если вы добавили строку в файл .htaccess в корне вашего сайта, то это действие (запрет индексации) будет распространяться на весь сайт. Вы также можете разместить файл .htaccess с этой строкой в любой папке, чтобы запретить индексацию только её.
Если вы достаточно продвинутый пользователь Apache, вы можете использовать директиву <Files>, чтобы указывать файлы какого именно типа запрещены для индексации.
Например, запрет для индексации всех файлов с расширением .PDF:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
Запрет для индексации всех файлов изображений (.png, .jpeg, .jpg, .gif):
<Files ~ "\.(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Files>
Блокировка доступа поисковым системам с помощью mod_rewrite
На самом деле, всё, что было описано выше, НЕ ГАРАНТИРУЕТ, что поисковые системы и запрещённые роботы не будут заходить и индексировать ваш сайт. Есть роботы, которые «уважают» файл robots.txt, а есть те, которые его просто игнорируют.
С помощью mod_rewrite можно закрыть доступ для определённых ботов
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Google [NC,OR]
RewriteCond %{HTTP_USER_AGENT} Yandex [NC]
RewriteRule ^ - [F]
Приведённые директивы заблокируют доступ роботам Google и Yandex для всего сайта.
Если, допустим, нужно закрыть для индексирования только одну папку report/, то следующие директивы полностью закроют доступ к этой папке (будет выдаваться код ответа 403 Доступ Запрещён) для сканеров Google и Yandex.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Google [NC,OR]
RewriteCond %{HTTP_USER_AGENT} Yandex [NC]
RewriteRule ^report/ - [F]
Если вам интересна блокировка доступа для поисковых систем к отдельным страницам и разделам сайта с помощью mod_rewrite, то пишите в комментариях и задавайте ваши вопросы – я подготовлю больше примеров.
Смотрите также: Полное руководство по mod_rewrite
Как запретить роботам доступ к ссылкам на определённом порту
Предположим, есть частный веб-сервер, настроенный на нетрадиционный порт (скажем, 6677). Все люди могут иметь доступ ко всем URL-адресам сайта на порту 6677. Ссылки с mysite.ru:6677 также проиндексированы Google, что может быть нежелательно.
Итак, как я могу запретить доступ к страницам сайта в robots.txt на нестандартном порте?
Если вы хотите запретить сканеру доступ к example.com:6677 с помощью robots.txt, вам просто нужно разместить файл robots.txt на соответствующем порту, то есть: http://example.com:6677/robots.txt
Спецификация не позволяет указывать порт в самом файле robots.txt. Все указанные пути используют тот же протокол, номер порта и хост, с которого осуществляется доступ к файлу.
Но, как уже говорилось в этой статье, запрет в robots.txt необязательно предотвращает индексирование URL-адреса; он предотвращает попадание в индекс поисковых систем.
То есть, предыдущий совет подойдёт для тех, у кого сайт на нестандартном порту является отдельным виртуальным хостом со своим собственным содержимым.
Но если один и тот же сайт доступен как с порта 80, так и с порта 6677, но только порт 6677 должен быть заблокирован для поисковых роботов, то предыдущий способ не подойдёт. Поскольку оба порта обращаются к одному и тому же сайту, они оба будут использовать общий файл robots.txt, и поэтому оба сайта будут заблокированы, если только разные файлы robots.txt не показываются зависимости от того, какой порт использовался для доступа к сайту.
В такой ситуации необходимо проверить порт в серверном скрипте и отправить клиенту соответствующий тег META или заголовок HTTP-ответа. В PHP вы можете сделать это примерно так:
<?php
// Блокируем роботов от доступа к порту 6677
if ($_SERVER['SERVER_PORT'] == '6677') {
header('X-Robots-Tag: noindex');
}
?>
Помните, что все заголовки должны выводиться строго до отправки других данных, поскольку после отправки данных заголовки уже отправлены и изменить их позже невозможно — это вызовет ошибку в PHP.
Можно пойти кардинально и запретить доступ поисковым систем к определённому порту, добавив примерно следующие правила в файле .htaccess:
# Блокируем доступ Google к порту 6677:
RewriteCond "%{SERVER_PORT}" "^6677$"
RewriteCond %{HTTP_USER_AGENT} Google [NC]
RewriteRule .* - [F]
# Блокируем доступ Yandex к порту 6677:
RewriteCond "%{SERVER_PORT}" "^6677$"
RewriteCond %{HTTP_USER_AGENT} Yandex [NC]
RewriteRule .* - [F]
8. Готовые решения для запрета индексирования сайта поисковыми системами
Билеты на автобусы, паромы и поезда, в том числе стыковочные маршруты:
Авиабилеты на международные и местные направления по минимальным ценам:
Связанные статьи:
- Как поисковым системам запретить индексирование только главной страницы сайта (100%)
- Как защититься от спама через формы обратной связи (79.1%)
- Как в mod_rewrite блокировать по Referer, User Agent, URL, строке запроса, IP и в их комбинациях (58.4%)
- Как бороться с ботами на сайте (58.4%)
- Как блокировать доступ к сайту с конкретного сайта-букса или любого другого сайта с негативным трафиком (58.4%)
- Считаем калории чтобы сбросить вес (RANDOM - 50%)
Здравствуйте Автор подскажите, а как закрыть все файлы от индексации типа:
самое близкое по значению, но тут папка
Если, допустим, нужно закрыть для индексирования только одну папку report/, то следующие директивы полностью закроют доступ к этой папке (будет выдаваться код ответа 403 Доступ Запрещён) для сканеров Google и Yandex.
RewriteEngine On RewriteCond %{HTTP_USER_AGENT} Google [NC,OR] RewriteCond %{HTTP_USER_AGENT} Yandex [NC] RewriteRule ^report/ - [F]А вот как закрыть (а может лучше перенаправление на главную) именно страниц по маске *.html с помощью mod_rewrite подскажите пожалуйста
Заранее Спасибо, С Уважением Тс
Приветствую! Для настройки индексации я бы в первую очередь рекомендовал использовать файл robots.txt. Для того, чтобы запретить индексировать все страницы, которые оканчиваются на .html, в файл robots.txt запишите:
И всё!
Если вам всё равно хочется использовать mod_rewrite, то помните, что без острой необходимости не нужно делать так, чтобы показывался разный контент для пользователей и для поисковых систем, поскольку это может быть воспринято как клоакинг.
Тем не менее, если хотите с помощью mod_rewrite перенаправлять на главную страницу все запросы поисковых роботов к адресам, заканчивающимся на .html, то следующие правила в файле .htaccess сделают это:
RewriteCond %{HTTP_USER_AGENT} Google [NC,OR] RewriteCond %{HTTP_USER_AGENT} Yandex [NC] RewriteRule .*\.html$ / [R]Есть еще пару вопросов в robots.txt (уже сделано) у меня так Disallow: /*.html это верно или обязательно добавить $ ?
для .htaccess вот так сделал
RewriteCond %{HTTP_USER_AGENT} Google [NC,OR] RewriteCond %{HTTP_USER_AGENT} Yandex [NC]знакомый посоветовал последнюю строчку вот так
может страницы лучше блокировать чем перенаправлять?
Символ $ означает конец строки. В этом правиле он для того, чтобы не было ложных срабатываний, если, к примеру, .html встретится где-нибудь в неожиданной части имени файла или в передаваемой переменой, то опять же, эта страница будет закрыта от индексации. Может такая ситуация и не возникнет, но если возникнет, то будет сюрпризом для вас.
В общем, то, что вам порекомендовали, подойдёт для блокировки доступа. Что лучше, блокировать или перенаправлять — не знаю. Редиректы лучше без особой нужды не использовать — со стороны это может выглядеть подозрительно, особенно если они делаются только для поисковых систем — опять же, можно подумать на клоакинг.
Добрый день, подскажите зеленому.
На сайте есть страницы со статьями ( картинки+текст). внизу каждой статьи есть блок " читатйте так же"- в котором есть изображние+ анотация другой статьи из этого же раздела.
Заметил такой "косяк"- робот индексирует все картинки и те что отнносятся к статье и те что предложены из блока читайте также под одну статью.
как запретить индексировать именно блок "читатйте так же"
Добрый день!
Скажите, пожалуйста, как будет правильно закрыть от индексации в этой ссылки https://site.ru/product/lobovoe-steklo-4133agnblhmv1b-fyg/?format=application/ld+json вот эту часть /?format=application/ld+json
Disallow: /*?*format=
так будет правильно?
Если нужно заблокировать страницы с одной и той же строкой, то есть если всегда format=application/ld+json, то правильно так:
Если же значение format могут быть разными, например, format=application/ld+xml и все их нужно заблокировать, то правильно будет так:
Второй вариант заблокирует вообще все страницы, в которых присутствует строка ?format=.
После редактирования файла robots.txt, не забудьте сделать проверку в Яндекс.Вебмастере и Поисковой консоли Google как тут тоже показано.
Спасибо большое! Очень помогли
Добрый день.
Подскажите как закрыть страницы где в адресе 2 слэша и более ///
Таже закрыть где вконце в адресе нет слеша сайт.ru/каталог/страница
Оставить только такие: сайт.ru/каталог/страница/
Приветствую! Закрывать страницы от индексации, которые различаются количеством слэшей, — это неправильный подход. Правильно в этом случае сделать так, чтобы таких страниц не было.
Несколько слэшей может появляться когда ссылка на внутреннюю страницу создаётся в PHP коде, например, когда она получается из строк «/cat/» и «/phones/», то в результате будет «/cat//phones/». В этом случае нужно исправить эти недочёты.
Другой вариант появления страниц с несколькими слэшами, когда кто-то вручную вводит неправильный адрес на вашем сайте, например, «/cat///phones/», а сайт правильно его понимает и просто отображает страницу без редиректа. В результате такая страница также может попасть в индекс поисковых систем — чтобы этого не было, нужно настроить редирект. Легче всего это сделать с помощью mod_rewrite.
Удаление лишних слешей в адресе URL
Например, страница /catalog///stranica.html доступна и открывается. Чтобы избежать такой ситуации и не плодить бесконечное число дублей следует записать следующий редирект:
RewriteEngine on RewriteBase / RewriteCond %{HTTP_HOST} !="" RewriteCond %{THE_REQUEST} ^[A-Z]+\s//+(.*)\sHTTP/[0-9.]+$ [OR] RewriteCond %{THE_REQUEST} ^[A-Z]+\s(.*)//+\sHTTP/[0-9.]+$ RewriteRule .* http://%{HTTP_HOST}/%1 [R=301,L] RewriteCond %{REQUEST_URI} ^(.*)//(.*)$ RewriteRule . %1/%2 [R=301,L]Здесь последовательно используется два правила для того, чтобы удалять многократные слеши из любой части URL: начала, середины, конца.
Это же касается наличия или отсутствия конечного слэша — можно выбрать любой вариант, но только один — это называется «канонический вид». Если движок вашего сайта не умеет работать с этим, то также на помощь придёт mod_rewrite.
Принудительное добавление конечного слеша к адресу сайта
Если вам нужно добавить к URL конечный слеш (в том случае, если он отсутствует), то воспользуйтесь этим правилом перезаписи:
RewriteEngine on RewriteCond %{REQUEST_FILENAME} !-f RewriteRule ^(.*[^/])$ /$1/ [L,R=301]Примеры взяты из «Полное руководство по mod_rewrite».
В результате вы добьётесь того, что не нужно будет исключать из индексации страницы без слэша на конце и с множественными слэшами подряд по той причине, что такие страницы просто не будут существовать. Это намного более правильный метод, поскольку если кто-то сделает ссылку на страницу в неканоническом виде, то такая страница всё равно проиндексируется! Запреты в файле robots.txt не помогут — страницы, на которые даны ссылки с внешних источников, попадают в индекс в любом случае.
День добрый! Намедни обнаружил в вебмастере яндекс, что индексируются изображения капчи. Будьте добры объясните чайнику, как правильно прописать в роботс запрет на индексацию, вот пример: сайт/image_captcha?sid=795459&ts=1567412565, переменных соответственно множество
Приветствую!
Скорее всего, по пути /image_captcha вообще ничего не должно индексироваться — независимо от параметров. Поэтому можно просто заблокировать целиком весь этот путь для индексации:
Спасибо! Прописал в роботс, проверил несколько ссылок в вебмастере, пишет, что страница запрещена к индексированию.
Здравствуйте.
Для этого сайта использую такой robots.txt
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-json/
Disallow: /xmlrpc.php
Disallow: /readme.html
Disallow: /*?
Disallow: /?s=
Allow: /?pg=
Allow: /*.css
Allow: /*.js
Sitemap: https://voynablog.ru/sitemap.xml
Гугл указывает, что страница https://voynablog.ru/index.php?page_id=99&pg=3
хотя и закрыта от индексации в robots.txt, но проиндексирована. Однако это может стать ошибкой в будущем. Это страницы карты сайта для пользователей. Я попыталась их открыть строчкой Allow: /?pg= , но похоже, что она не работает. Как посоветуете мне открыть для индексации указанные страницы карты сайта?
Приветствую! Чтобы разрешить для индексации страницу https://voynablog.ru/index.php?page_id=99&pg=3 нужно использовать следующее правило:
Это правило разрешит любую страницу указанного вида. Если вам нужно разрешить именно одну страницу, то вы можете указать её буквально:
Хотя меня смущает адрес voynablog.ru/index.php?page_id=99&pg=3, если это WordPress, то скорее всего адрес такой: voynablog.ru/?page_id=99&pg=3, тогда правило:
Или можете указать оба правила.
Или правило для обоих случаев:
Иногда Гугл игнорирует запрет в файле robots.txt, особенно если с другого сайта ведёт ссылка на страницу, запрещённую для индексации — в этом случае страница всё равно будет проиндексирована.
Здравствуйте.
Спасибо за грамотный ответ. Но положительного результата я так и не получила, добавляя в роботс различные варианты открытия страницы https://voynablog.ru/index.php?page_id=99&pg=3 для индексации. М.б. я делаю что-то не так, или Гуглу нужно много времени, чтобы принять новые изменеия в роботсе.
Как я всё сделала:
1. Открыла robots.txt в Goole Search Console
2. Внесла изменение вместо строчки Allow: /?pg= вставила строку Allow: /*?page_id=99&pg=3. Пробовала и другие варианты вами указанные - результат всегда один.
3. Проверила файл, нажала кнопку Отправить
4. Появилось окно с тремя действиями. Обновила robots.txt на сайте.
5. Нажала отправить.
6. Какую страницу обновить так и не поняла: Обновила главную страницу сайта и https://voynablog.ru/index.php?page_id=99&pg=3. Если этот адрес поставить в адресную строку, то загружается https://voynablog.ru/karta-bloga/?pg=3
7 Посмотрела индексацию https://voynablog.ru/index.php?page_id=99&pg=3 - проиндексировно, несмотря на блокировку в роботс. Проверила страницу с адресом https://voynablog.ru/karta-bloga/?pg=3 - не проиндексирована, запросила индексацию - получила отказ - страница заблокирована в robots.txt
Либо Гугл очень медленно реагирует на изменения, либо я делаю что-то не так. Подскажите, пожалуйста, - в чём моя проблема.
Я временно скопировал содержимое вашего файла robots.txt к себе на сайт (suay.ru)
После этого я перешёл в инструменты Search Console (адрес https://www.google.com/webmasters/tools/robots-testing-tool), запросил обновление файла robots.txt (как это сделать написано в статье) и сразу же проверил страницу, которая аналогична вашей, то есть _https://suay.ru/index.php?page_id=99&pg=3 (изменён только домен).
И получил результат, что страница доступна благодаря правилу Allow: /*?page_id=99&pg=3:
Вся проверка вместо с копированием файла robots.txt заняла минуты две. Что тут можно сделать неправильно я не понимаю…
Так у меня тоже получается. А вот если я проверяю https://voynablog.ru/index.php?page_id=99&pg=3
в Goole Search Console в разделе "Проверка URL", то выдаётся то, что я писала в предыдущем письме. Получается, что надо инициализировать вновь проверку ошибок с ковым роботс в корне сайта. И ждать результата.
Здравствуйте У меня есть вопрос. У меня есть сайт. На этом сайте Я никогда не ставила компонент joomsport ни его плагини ни модули. Но вот в какой то момент Яндекс стал находить на моём сайте существующие страницы, но ссылки на эти страницы были изменены. В середине ссылки вставлен "component/joomsport/table/" вот этот несуществующий компонент. Ссылка должна быть например такого вида https://site.ru/index.php/rex/novosti//skahat-knigi-awtora.html а Яндекс находит https://site.ru/index.php/component/joomsport/table/rex/novosti//skahat-knigi-awtora.html Как это убрать никак не могу понять(((
Здравствуйте, уважаемый автор! Помогите пожалуйста начинающему)) Есть страница экскурсии /boat/paradnyj-peterburg или /boat/razvodnye-mosty на каждую дату и время в адресной строке добавляются цифры /boat/paradnyy-peterburg/6344 или /boat/razvodnye-mosty/6354 и поисковые роботы индексируют новые страницы в большом кол-ве, а это плохо для СЕО. Подскажите пожалуйста как запретить индексировать страницы с дополнительными цифрами? они всегда разные…… Спасибо огромное заранее.
Приветствую!
Вы не написали, страниц действительно две или страниц много? Допустим страниц много и в каждой из них в URL встречается дефис в этом месте:
Получаем шаблон, соответствующий данным страницам:
Теперь нужно сделать шаблон, который соответствует страницам, запрещённым для индексации. Если выразить словами, то запрещены к индексации страницы /boat/*-*/ после которых в URL идёт хотя бы одна цифра. Эти шаблоны не поддерживают полноценный синтаксис регулярных выражений, поэтому мы не можем указать «любая цифра». Но цифр немного, поэтому мы можем пойти на хитрость и просто перечислить их все, получается:
Проверяем:
Страниц с экскурсиями достаточно много и где то есть дефис например:
/boat/salyut-v-den-vmf-s-borta-teplohoda
/boat/pod-razvodnymi-mostami
/boat/alye-parusa
а где-то его нет
/rent/konstantin
Но как я понял я могу указать в robors.txt к каждой экскурсии так:
или сделать шаблоны разных вариантов:
1) /boat/*-*/ (перечисляем цифры)
2) /boat/*-*-*/(перечисляем цифры)
2) /boat/*/(перечисляем цифры)
и.т.д.
Я всё верно понял? Извиняюсь за глупые вопросы если что….Совсем недавно начал изучать.
Обратите внимание, вы случайно написали адрес сайта — если хотите, могу отредактировать комментарий и убрать адрес.
Да можно сделать так:
1) /boat/*-*/ (перечисляем цифры)
2) /boat/*-*-*/(перечисляем цифры)
3) /boat/*/(перечисляем цифры)
Причём второй вариант является излишним, поскольку все те, которые «/boat/*-*-*/» уже охватываются правилом «/boat/*-*/».
То есть достаточно так:
1) /boat/*-*/ (перечисляем цифры)
3) /boat/*/(перечисляем цифры)
Не забывайте на всякий случай перепроверять работу правил в Яндекс.Вебмастере или в Search Console — как это делать написано в статье.
Огромное вам спасибо!!! Пошел внедрять и проверять)))
Адрес сайта убрал — письмо попало в спам, поэтому не сразу отреагировал.
Уберите пожалуйста адрес сайта, поторопился и случайно его отправил) Еще раз громадное спасибо.
Небольшое добавление — первый вариант тоже является излишним. Правила вида: «/boat/*/(перечисляем цифры)» уже охватывают «/boat/*-*/ (перечисляем цифры)», потому что звёздочка это «что угодно», в том числе и дефис.
Здравствуйте, уважаемый автор!)) Снова к вам со своим вопросом)
СДелал как вы говорили и при проверке файла robots.txt. в яндекс вебмастере выдает, что страницы запрещены для индексации, но роботы не перестают добавлять новые страницы. Парадокс в том, что при проверке опять таки новых добавленных страниц стоит запрет на них, но добавления продолжаются приложу два фото, чтобы было нагляднее. Быть может подскажите как с этим бороться??Оо
Приветствую! ИМХО, поисковые системы очень инертны, то есть сделанные изменения фактически могут начать учитываться не сразу. Я бы подождал хотя бы пару тройку недель, чтобы окончательно убедиться, что проблема имеется.
Как вариант, написать в службу поддержку Яндекс.Вебмастера.
Ещё один вариант, с помощью mod_rewrite поисковым ботам выдавать код ошибки 404 на указанные страницы.
Здравствуйте!
Помогите, пожалуйста, как лучше запретить индексацию страниц, которые стали индексироваться при неправильно прописанной ссылке. Это было давно, случайно в конце ссылки не поставил слэш: http://site.ru/page-bad/ , и Яндекс а потом и Гугл стали индексировать страницы, которых не должно быть. Что-то вроде http://site.ru/page1/page-bad/ http://site.ru/page2/page-bad/ http://site.ru/page3/page-bad/
Т.е. CMS сама не генерирует страницы 2 уровня, они образуются только при обращении к ним. И поисковики их индексируют. Содержание аналогично страницам первого уровня. Т.е. происходит генерация дублей. Ту неправильную ссылку сразу же удалил, но поисковики их все равно индексируют L
Как можно сделать запрет индексации по маске http://site.ru/*/page-bad/ или лучше, чтобы такие страницы выдавали ошибку 404?
или может быть как-то можно сделать перенаправление со страниц _http://site.ru/page1/page-bad/ на _http://site.ru/page1/ по шаблону, как в примере с лишними слэшами:
Добрый день, хочу удалить от индексации все страницы которые в url имеют текст etext= подскажите пожайлуста, провильно я прописал в robots.txt Disallow: /*?*etext=
И подскажите пожайлуста как запретить индексацию записей и страниц на сайте, у меня интернет магазин, хотелось бы чтобы только товары индексировались.
Заранее извиняюсь за тупость. Спасибо большое.
Автор, привет)
Подскажи как убрать из индексации ТОЛЬКО главную страницу?
Не спрашивай зачем)
Приветствую! Вопрос интересный, посмотрите заметку «Как поисковым системам запретить индексирование только главной страницы сайта».
Добрый день.
Как закрыть страницы /tours/1709724899/1795869958/7/ это технические страницы, которые получает пользователь при поиске туров, они не должны индексироваться.
Никак не пойму, зачем прописывать кучу правил на разные параметры после знака "?" почему просто не закрыть от индексации все страницы с самим знаком "?" ? Они же все равно все не должны индексироваться
Приветствую! Это неверное суждение, по крайне мере для этого сайта и для половины других сайтов в Интернете. К примеру, адрес этой страницы https://suay.ru/?p=790. Если я закрою для индексации все адреса со знаком «?», то кроме главной страницы не будет доступно ничего.
Добрый день.
Страница просканирована, но не проиндексирована и таких страниц очень много, пример:
/?2541-константин-избяга-от-надя-lupa-bg
/y-demo?id=1701
/Ln2Nciu_-9rMM4df.html
Cтраницы планирую закрыть от индексации. Верно ли будет прописать в роботс:
User-agent: *
Host: https://site.com
Sitemap: https://site.com/sitemap.xml
Disallow: /*?*
Disallow: *.html$
Добрый день.
На kworke заказал специалиста что бы тот убрал ридеректы страниц самих на себя, вместо этого он прописал / в "Постоянных ссылках"
Пока я разобрался и устранил, что он сделал, Яндекс и Гугл за сутки выдали в поиск дубли страниц с /.
Соответственно просел трафик и поиск.
Подскажите пожалуйста, как закрыть в robot.txt индексацию дулбь страниц с /
основная страница:
https://sait.ru/рубрика
дубль:
https://sait.ru/рубрика/